
CI Days 2015
Posters
POSN – Personal Online Social Network
Authors – Eric Klukovich (UNR); Esra Erdin (UNR); Dr. Mehmet H. Gunes (UNR); Gurhan Gunduz (UNR)
Presenters – Vinh Le (UNR); Melanie Neff (UNR); Royal Stewart (UNR)
University of Nevada, Reno
A growing concern for end users of online social networks (OSN) is the privacy and control of user data due to the client-server architecture of the current ecosystems. We introduce Personal Online Social Network (POSN), a privacy preserving decentralized social network platform, which mimics real life social interactions. In particular, we decentralize the OSN platform and give direct control of the information to the user. The distributed platform removes central authorities from the OSN and users share their content only with intended peers through mobile devices. This decentralized system ensures that interaction happens between friends and third parties cannot access the user content or relationships. To be able to efficiently share objects and provide timely access in the POSN platform, we take advantage of free storage clouds to distribute encrypted user content. The combination of phone-to-phone applications with cloud infrastructure would address the main limitation of peer-to-peer systems, i.e., availability, while enjoying the benefits of peer-to-peer systems, i.e., no central authority and scalability.
 Software Process Models: A Survey
Software Process Models: A Survey

Authors – Rui Wu (UNR); Dr. Sergiu Dascalu (UNR); Dr. Frederick C. Harris, Jr. (UNR)
Presenters – Vinh Le (UNR); Melanie Neff (UNR); Royal Stewart (UNR)
University of Nevada, Reno
The software process model has become more and more significant these days because it helps developers save time, ensure product quality, make management easier, enable project visibility, and reduce risks pertaining to software development. However, there are some shortcomings with traditional software process models. For example, when new requirements arise later in the project, waterfall is not flexible enough to accommodate them by moving back to an earlier phase. In this study, we present an overview of over 80 scientific papers focused on software process models, and propose a classification of such processes in four categories, based on their main emphasis: maintainability, efficiency, dependability, and acceptability. The maintainability segment encompasses flexibility and extensibility. The efficiency group includes high speed development, large tasks and large group collaborations, extensive reuse, and choosing the best software process models for given projects. The dependability segment covers robustness and security. The acceptability group consists primarily of solutions for avoiding user errors and increasing the user experience. Based on the survey conducted, we identified several research trends in software process models, which are also outlined in the poster.
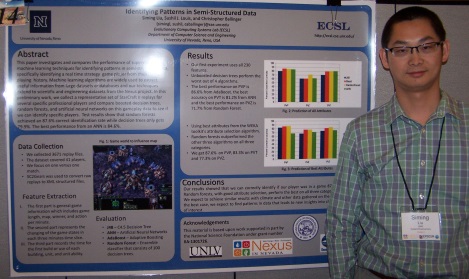
Identifying Patterns in Semi-Structured Data
Authors – Siming Liu (UNR); Dr. Sushil J. Louis (UNR); Christopher Ballinger (UNR)
Presenters – Vinh Le (UNR); Melanie Neff (UNR); Royal Stewart (UNR)
University of Nevada, Reno
This paper investigates and compares the performance of supervised machine learning techniques for identifying patterns in semi-structured data, specifically identifying a real time strategy game player from their playing history. Machine learning algorithms are widely used to extract useful information from large datasets or databases and our techniques extend to scientific and engineering datasets from the Nexus project. In this preliminary work, we collect a representative set of StarCraft II replays for several specific professional players and compare boosted decision trees, random forests, and artificial neural networks on this gameplay data to see if we can identify specific players. Test results show that random forests achieved an 87.6% correct identification rate while decision trees only gets 79.9%. The best performance from an ANN is 84.6%.
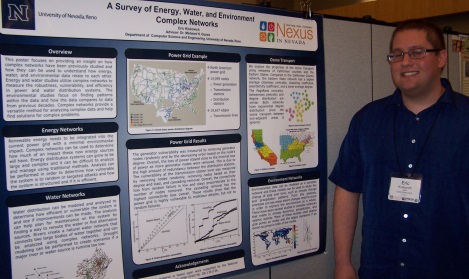
A Survey of Energy, Water, and Environment Complex Networks
Authors – Eric Klukovich (UNR); Dr. Mehmet H. Gunes (UNR)
Presenters – Vinh Le (UNR); Melanie Neff (UNR); Royal Stewart (UNR)
University of Nevada, Reno
Complex networks can be used to get a better understanding of how energy, water, and environmental data relate to each other and to find patterns within the data. We focus on providing a detailed overview of some of the previous studies that use complex networks to study data in these areas. Many of the energy and water studies utilized complex networks to measure the robustness, vulnerability, and efficiency of the distribution systems. The environmental studies focused on discovering patterns within the data and compared them to data from previous decades. These studies show that complex networks provide a versatile method for analyzing complex data and understanding how all of the data relates to each other. The use for complex networks is growing and many more studies will have to be done to not only find solutions to real world problems, but also get a better understanding of the relationships within the data.
 Micro service Architecture for the NRDC
Micro service Architecture for the NRDC

Authors – Vinh Le (UNR); Melanie Neff (UNR); Royal Stewart (UNR); Dr. Richard Kelley (UNR); Eric R. Fritzinger (UNR); Dr. Frederick C. Harris, Jr. (UNR)
Presenters – Vinh Le (UNR); Melanie Neff (UNR); Royal Stewart (UNR)
University of Nevada, Reno
NRDC Microservice Architecture is a redesign of the already existing NRDC service and website that is ran by the Cyberinfrastructure group as a part of the National Science Foundation Track I grant. We are implementing a microservice architecture instead of the current monolithic architecture in order to increase scalability and to make the portal more robust. We have service modules that communicate with a PostGRES database that administers and holds data. These modules are independent of each other and can be replicated to account for times of heavy load on the services. We have also set up a service discovery and monitoring systems through Netflix’s own Eureka load balancing service. Eureka allows us to monitor each individual service for the amount of traffic that it is handling and to balance the load of traffic during times of heavy usage. With this new approach the NRDC will be a much more robust, easier to use system, and provide a sturdy base for storing research data in the state of Nevada.
Using Deep Learning Neural Network for Forecasting the Weather of Nevada
Authors – Moinul Hossain (UNR); Banafsheh Rekabdar (UNR); Dr. Sushil J. Louis (UNR); Dr. Sergiu Dascalu (UNR)
Presenters – Vinh Le (UNR); Melanie Neff (UNR); Royal Stewart (UNR)
University of Nevada, Reno
We investigate a deep learning Artificial Neural Network approach for creating weather forecast models using the climate data from the Nevada Climate Change Portal. Neural Networks are useful for modelling highly nonlinear and chaotic processes like weather. With the recent interest in deep learning Neural Networks, we explored the feasibility of a deep learning approach called Stacked Denoising Auto-Encoders for building forecast models that predict hourly air temperature. We considered historical hourly temperature, barometric pressure, humidity and wind speed data for building the model. We collected and processed the raw data from the Nevada Climate Change Portal subscribed sensors and use this data to empirically compare the performance of stacked denoising autoencoders against traditional neural nets at predicting temperature. Experimental test results show that, with a good choice of parameters, stacked denoising autoencoders achieved up to 98% accuracy in predicting temperature, beating traditional neural networks. Our results provide further empirical evidence of the broad applicability of deep neural networks.
 UNLV Cyberinfrastructure Node Design
UNLV Cyberinfrastructure Node Design

Authors – Xiangrong Ma, Dr. Yingtao Jiang (UNLV)
Presenters – Xiangrong Ma
University of Nevada, Las Vegas
We have designed and deployed a Cyberinfrastructure (CI) Cloud Cluster to support the Nexus research group. A new cloud architecture has been proposed and implemented based on the study of requirements and current computing technology.
At hardware level, powered with 96 Intel Xeon processor cores, the cluster is able to store and process large data-sets efficiently by distributing tasks among 10 servers simultaneously; On software side, we have build a highly optimized GNU/Linux operating system, bundled with Bigdata processing engine and scientific computing pack. We have gain an average 10-20% performance increase and up to 35X performance boost in some critical scientific computing package.
While we will continue work on connectivity with NCDC and field sensors to get data, we also planned to develop a series of tutorials to our research community about how to use this platform, with the hope that these new tools and technology would made a boost to our current and future research.

Power Quality Studies in Water Pumping and Water Treatment Plants
Authors – Christopher Hicks, Dr. Yahia Baghzouz (UNLV)
Presenters – Christopher Hicks(UNLV)
University of Nevada, Las Vegas
A variable-frequency drive (VFD) is an electronic controller that adjusts the speed of an electric motor by modulating the supply voltage and frequency. VFDs are enjoying rapidly increasing popularity at water and waste-water facilities, as they draw less energy while still meeting pumping needs. In addition to saving energy, VFDs offer several other advantages including “soft start” capability which lessens mechanical and electrical stress on the motor thus extending motor life, more precise control of processes, closer pressure tolerances in water distribution systems. However, because of the nature of this technology, VFDs can produce harmonic distortion on the utility side — which can affect the quality of power. On the motor side, VFDs cause other problems which stem from the high-frequency pulsed output voltage. Such pulses can be magnified by the impedance of the cable connecting the VFD to the motor thus putting high stress on the insulation. Furthermore, high-frequency common-mode voltages and currents may cause trouble with motor bearings. Both theoretical and experimental research will be conducted on how to prevent or reduce the severity of the above problems caused by VFDs.
 A Hybrid Method for Compression of Solar Radiation Data Using Neural Networks
A Hybrid Method for Compression of Solar Radiation Data Using Neural Networks

Authors – Bharath Chandra Mummadisetty, Astha Puri, Dr. Shahram Latifi
Presenters – Astha Puri, Bharath Chandra Mummadisetty
University of Nevada, Las Vegas
The prediction of solar radiation is important for several applications in renewable energy research. There are a number of geographical variables which affect solar radiation prediction, the identification of these variables for accurate solar radiation prediction is very important. This paper presents a hybrid method for the compression of solar radiation using predictive analysis. The prediction of minute wise solar radiation is performed by using different models of Artificial Neural Networks (ANN) namely Multilayer Perceptron (MLP), Cascade Feed Forward Back propagation (CFNN) and Elman Back propagation (ELMNN). Root Mean square error (RMSE) is used to evaluate the prediction accuracy of the three ANN models used. The information and knowledge gained from the present study will improve the accuracy of analysis concerning climate studies and help in congestion control.
The RMSE values for MLP, CFNN, and ELMNN are 5, 5.25, and 9.21 respectively. The maximum compression ratio obtained using MLP, CFNN, and ELMNN are 9.8, 9.66, and 7.47 respectively. Conclusively, the Multilayer perceptron (MLP) seems to be the most promising among the other two algorithms as it outperformed the others in RMSE and Compression Ratio.
 Analysis of Hyperspectral Image Compression Methods
Analysis of Hyperspectral Image Compression Methods
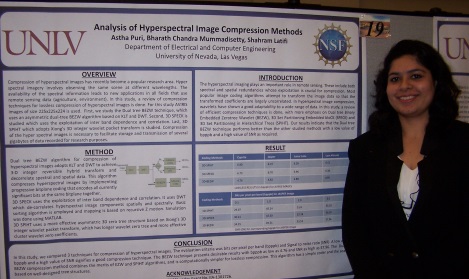
Authors – Astha Puri, Bharath Chandra Mummadisetty, Dr. Shahram Latifi
Presenters – Astha Puri, Bharath Chandra Mummadisetty
University of Nevada
The hyperspectral imaging plays an important role in remote sensing. Hyperspectral images include both spectral and spatial redundancies whose exploitation is crucial for compression. Most popular image coding algorithms attempt to transform the image data so that the transformed coefficients are largely uncorrelated. In hyperspectral image compression, wavelets have shown a good adaptability to a wide range of data. Some wavelet-based compression methods have been successfully used for hyper spectral image data. In many applications, Karhunen–Loève Transform (KLT) is the popular approach to decorrelate spectral redundancies. In this paper, a review of efficient compression techniques is done, with more emphasis on Binary Embedded Zerotree Wavelet (BEZW), 3D Set Partitioning Embedded bloCK (SPECK) and 3D Set Partitioning in Hierarchical Trees (SPIHT). The Airborne Visible/Infrared Imaging Spectrometer (AVIRIS) was developed by the NASA Jet Propulsion Laboratory in 1987 and provides spectral images with 224 contiguous bands. In our study, we used the standard AVIRIS images – Lunar Lake, Jasper, Cuprite and Low altitude to analyze various methods. The image size used was 225x225x224.
In comparison with the techniques discussed, the BEZW technique with bits per pixel per band (bpppb) of 4.76 and SNR (dB) of 57.96 outperforms other techniques. Also, it has lower computational cost, better performance, high efficiency and simplified coding algorithm.

A Framework for Environmental Monitoring with Arduino-based Sensors using Restful Web Service
Authors – Sungchul Lee, Dr. Juyeon Jo (UNLV)
Presenters – Sungchul Lee
University of Nevada
The Nevada Solar Energy-Water-Environment Nexus project generates a large amount of environmental monitoring data from variety of sensors. This data is valuable for all related research areas, such as soil, atmosphere, biology, and ecology. An important aspect of this project is promoting data sharing and analysis using a common platform. To support this effort, we developed a comprehensive architecture that can efficiently collect the data from various sensors, store them in a database, and offer an intuitive user interface for data retrieval. We employed Arduino-based sensors due to their flexibility and cost-effectiveness. Restful Web Service is used for communication with the Arduino-based sensors, and Google Charts service has been used for data visualization. This framework for sensor data monitoring with Web Service is expected to allow the Nevada Nexus project to seamlessly integrate all types of sensor data and to provide a common platform for researchers to easily share the data.
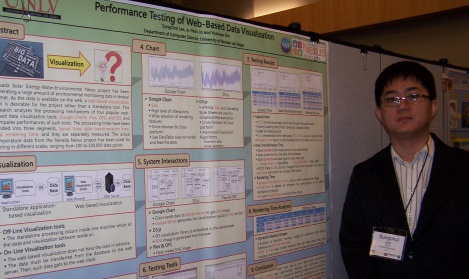
Performance Testing of Web-Based Data Visualization
Authors – Sungchul Lee, Dr. Juyeon Jo (UNLV)
Presenters – Sungchul Lee
University of Nevada
Many scientific applications generate massive data that requires visualization. For example, the Nevada Solar Energy-Water-Environmental Nexus project has been generating a large amount of environmental monitoring data in textual format. As the data is available on the web, a web-based visualization tool is desirable for the project rather than a standalone tool. This research analyzes the processing mechanisms of four popular web-based data visualization tools, that is, Google Charts, Flex, OFC, D3, and compares their performances. A standalone visualization tool, JfreeChart, have been also used for comparison. The processing times have been divided into three segments, layout time, data transformation time, and rendering time, and separately measured. The actual temperature data from the Nevada Nexus project has been used for testing in different scales ranging from 100 to 100,000 data points. The result shows that each visualization tool has its own ideal environment.


